
We planned a data conference with AI in 7 minutes flat
A behind-the-scenes look at how ChatGPT helped us build the Data in the D agenda


They say AI won’t replace you, someone using AI will. At last week’s Data in the D organizing committee meeting we were faced with the daunting task of putting together a conference schedule. Maybe that sounds easy to you. It isn’t. But this is the story how we replaced ourselves using AI and succinct, impactful prompts.

There are dozens of levers to pull when planning a conference. Session length, sequencing, location, lunch, keynote, happy hour - it’s just a ton. And I’ll be real, we were staring at a spreadsheet debating what to put where and for how long and it was 4:00 on probably the last nice Friday for six months here in Detroit and I and the rest of the team had enough.
So we turned to ChatGPT for help. Everything you see from here on out was done live on a Teams call and took about 7 minutes.
Structuring the conference schedule
We were struggling to establish the basic schedule - how long are the sessions, how long is lunch, etc. Rather than hashing it out, let’s see if AI can make it for us.

To me this is the goldilocks level of prompting - not too much info, not too little, just right. I could have loaded it up with ultimately irrelevant details, but why? It gave me a perfectly servicable response using just this.
GPT 5 will always suggest next steps for you. In this case, it suggested all sorts of stuff not pictured above which I ignored. I usually ignore its suggestions to be honest.
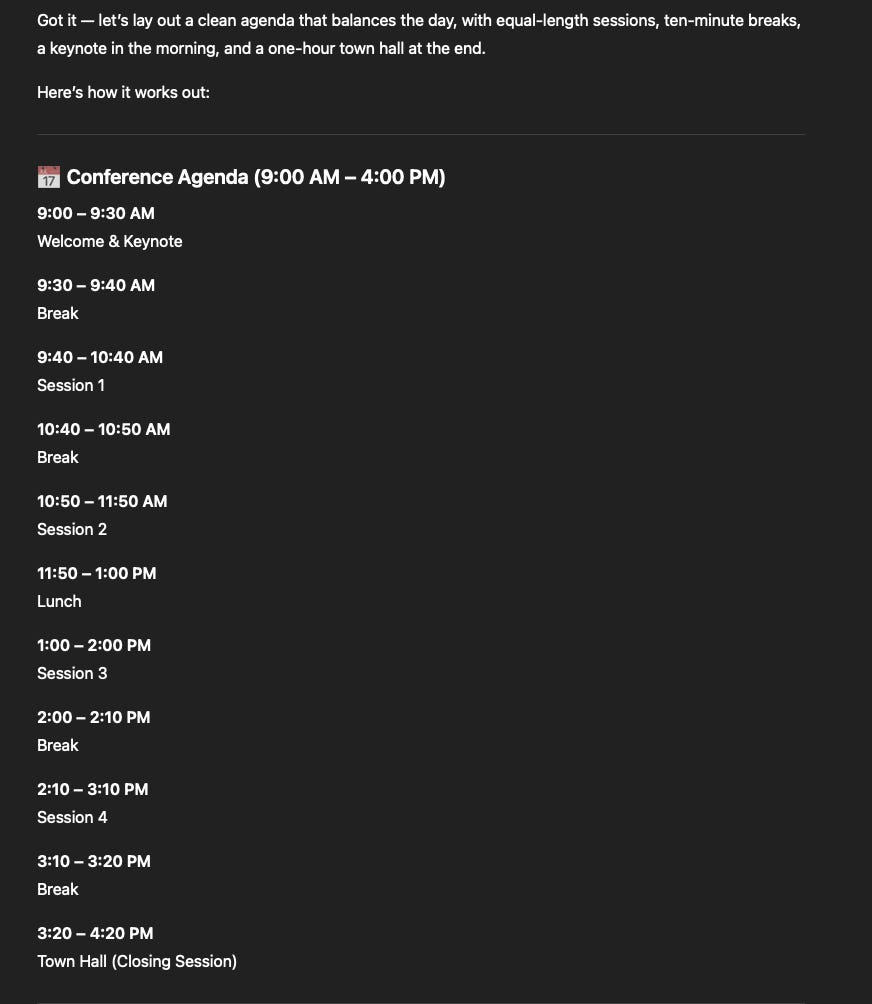
This was a good first stab, but Joe Reis, our keynote speaker, always brings the heat to a data conference and cramming him and a welcome into thirty minutes is silly so we iterated.
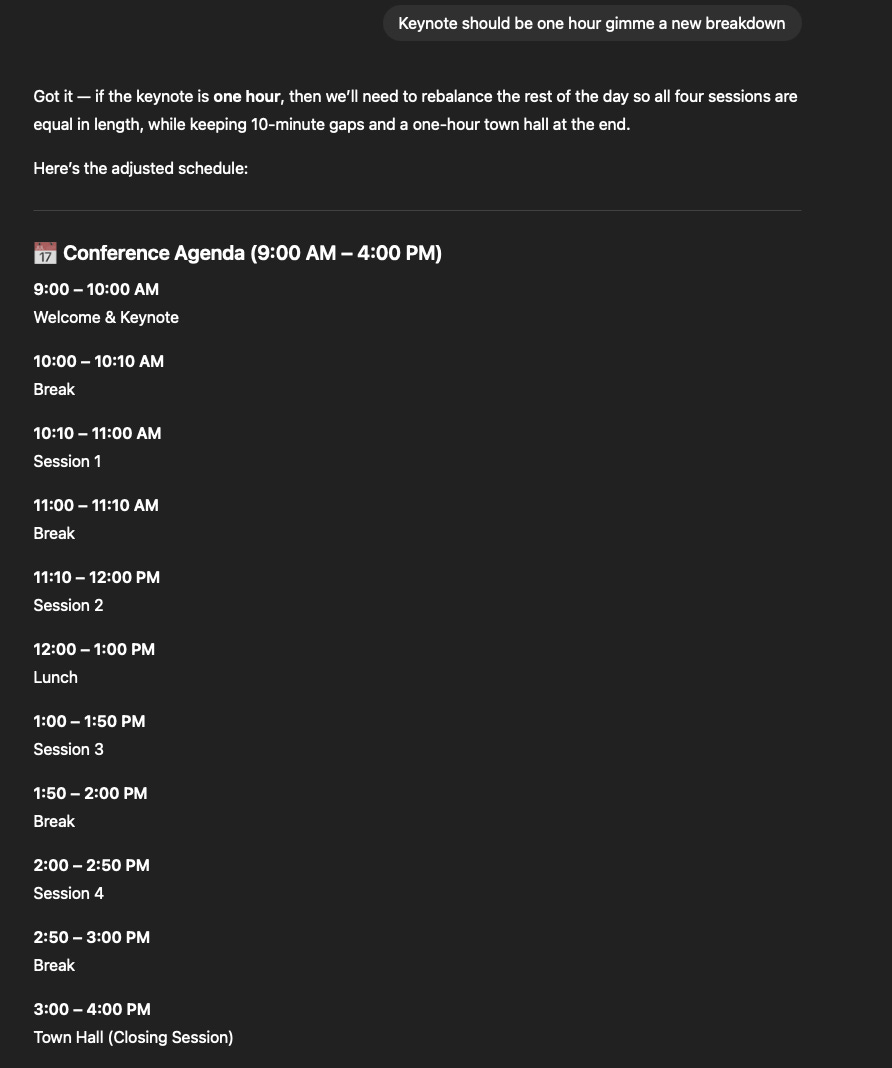
Getting closer, but that town hall is too tight. We need room for the participants to get comfortable and open up. Because we don’t want to just extend the conference, we have to trim somehwere.
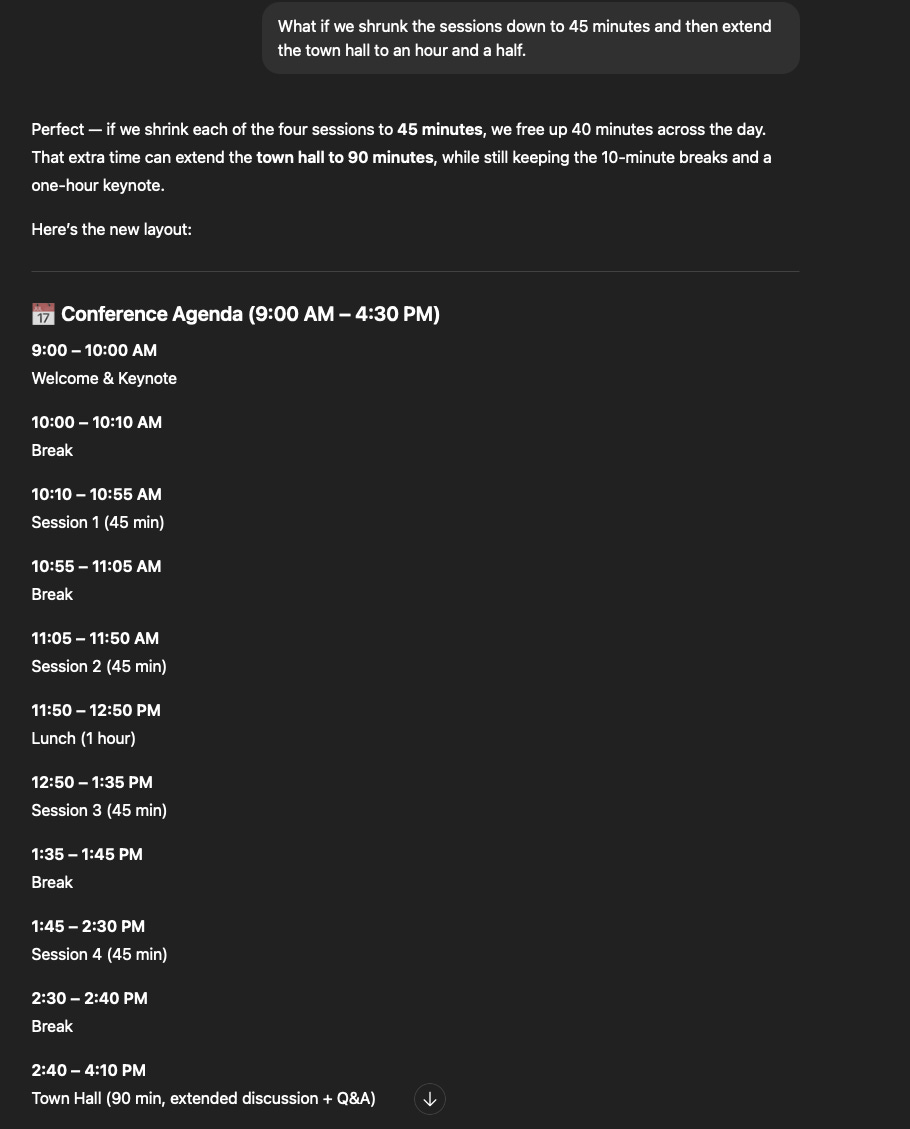
And there we had it. A reasonable, well structured conference schedule. But that’s the easy part. The hard part is the agenda and presentation sequencing. We used AI for that too.
Teaching our AI the conference context
Data in the D has four tracks with four presentations each focused on BI and Analytics, Data Culture, Data Engineering and Artificial Intelligence. With that mix we could have spend days debating the best sequence.
Instead, I uploaded a screenshot of the presentation spreadsheet that our organizer had shared on Zoom. The grain of the spreadsheet is at the presenter level, and since we have panel discussions there were more rows than we have presentations. But that was easy to explain to ChatGPT via a simple prompt.
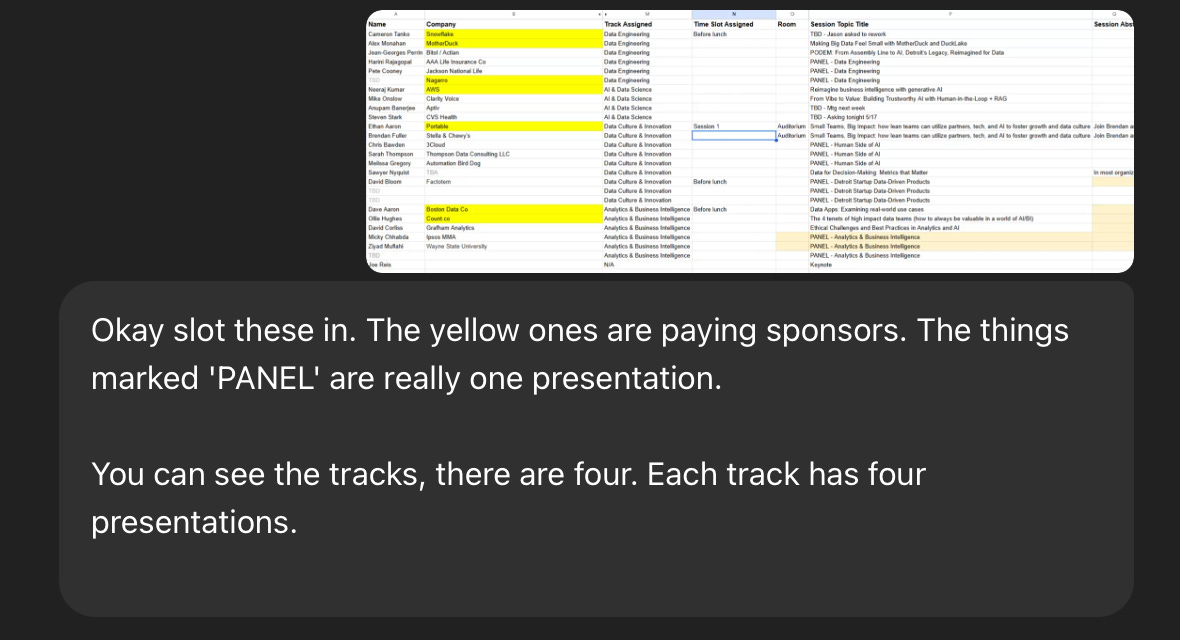
You can see how it picked up the necessary details without further explanation. At this point it understand our tracks and their titles, who our sponsors are, and the overall flow of the day. It even gave us a proposed agenda without me explicitly asking.
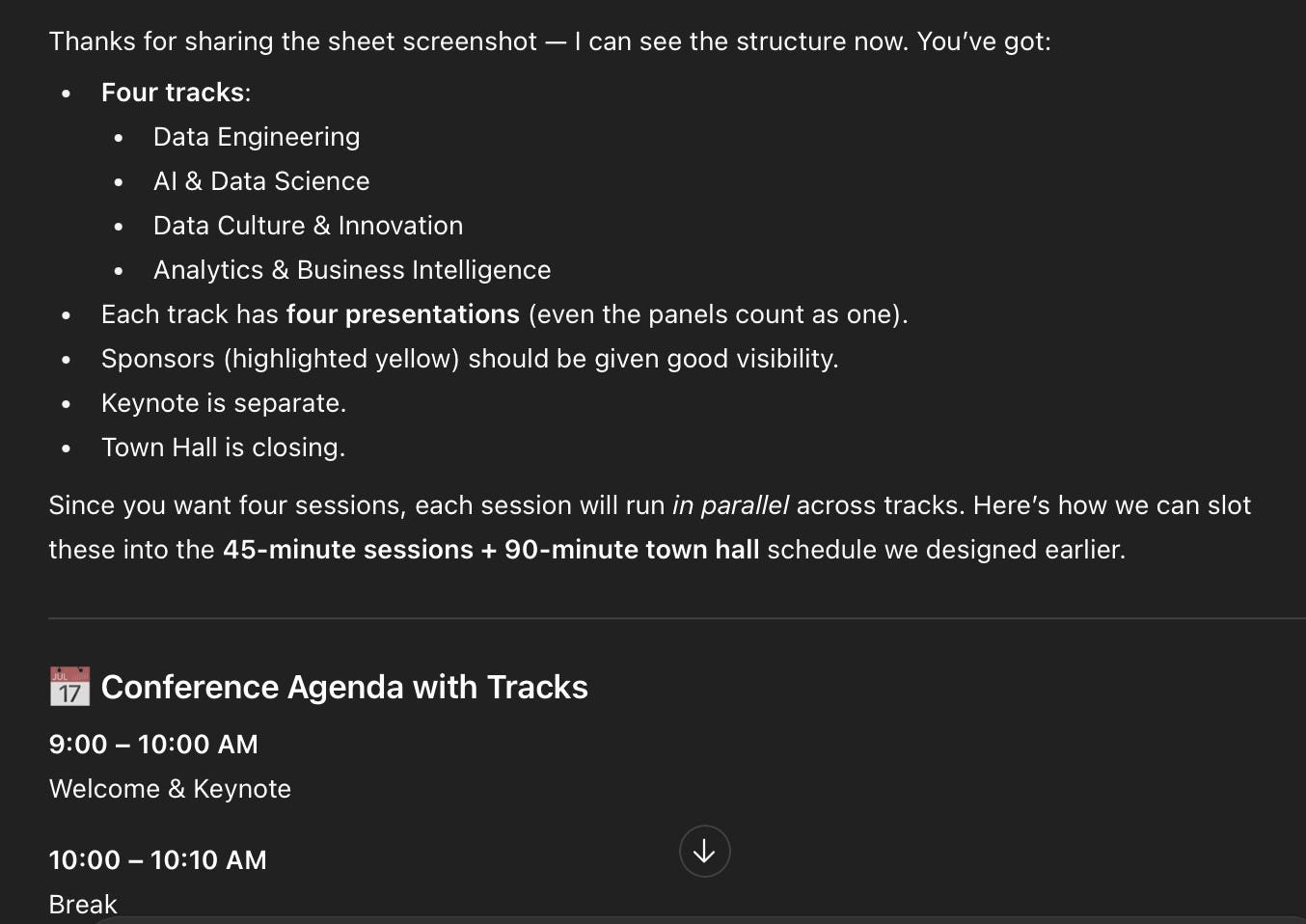
The agenda was in long text format and hard to read. So I asked for a table. Easy fix.
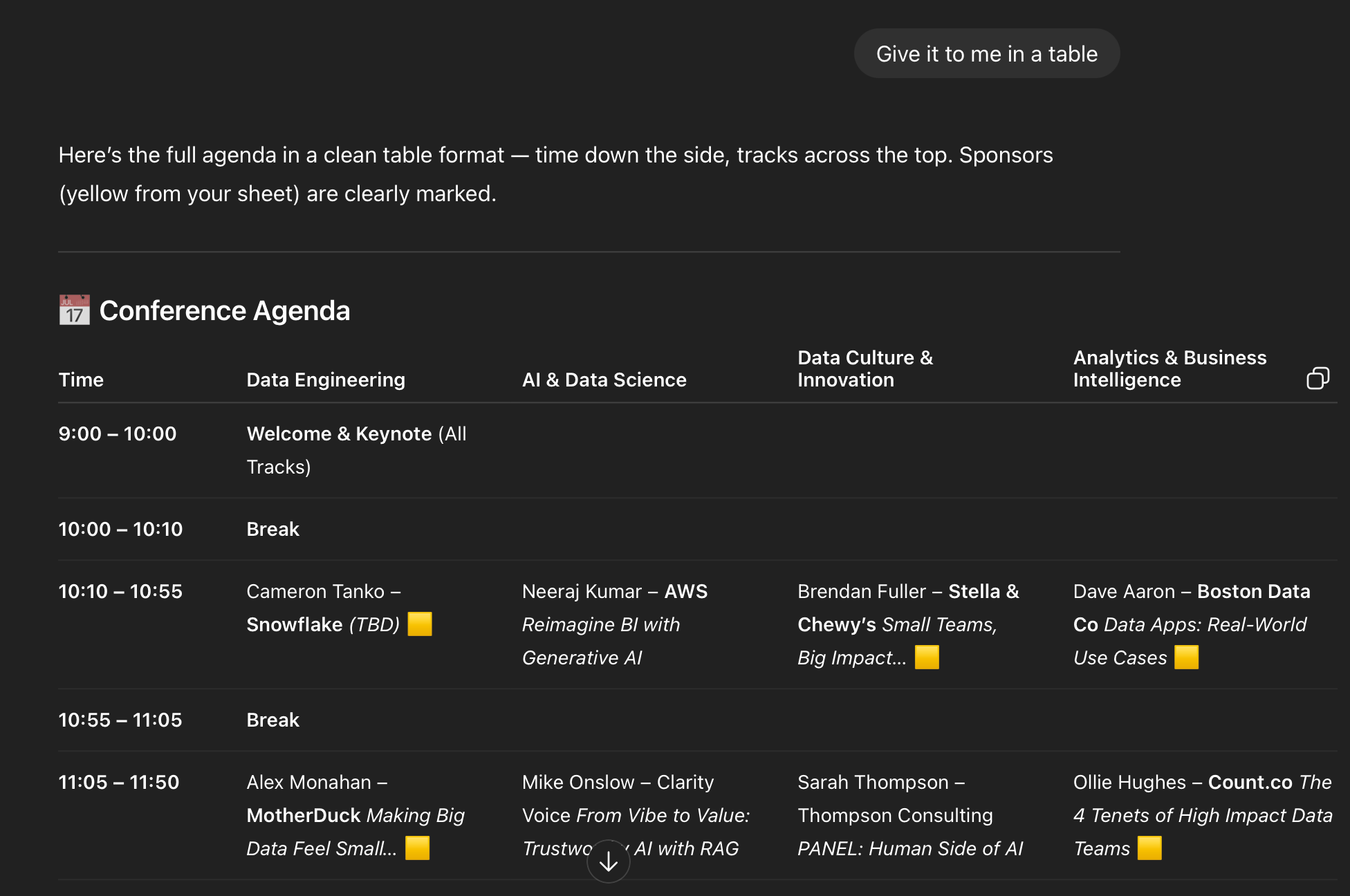
It got a few things wrong here - it has some people marked as sponsors who aren’t. But that’s not relevant to our goal. In fact, we could have just run with this proposed agenda, it was pretty good. But not perfect.
After reviewing together for two minutes, we suggested a few changes to the sequencing of two of the tracks to spread out the sponsored presentations and the panel discussions so that they don’t all overlap.
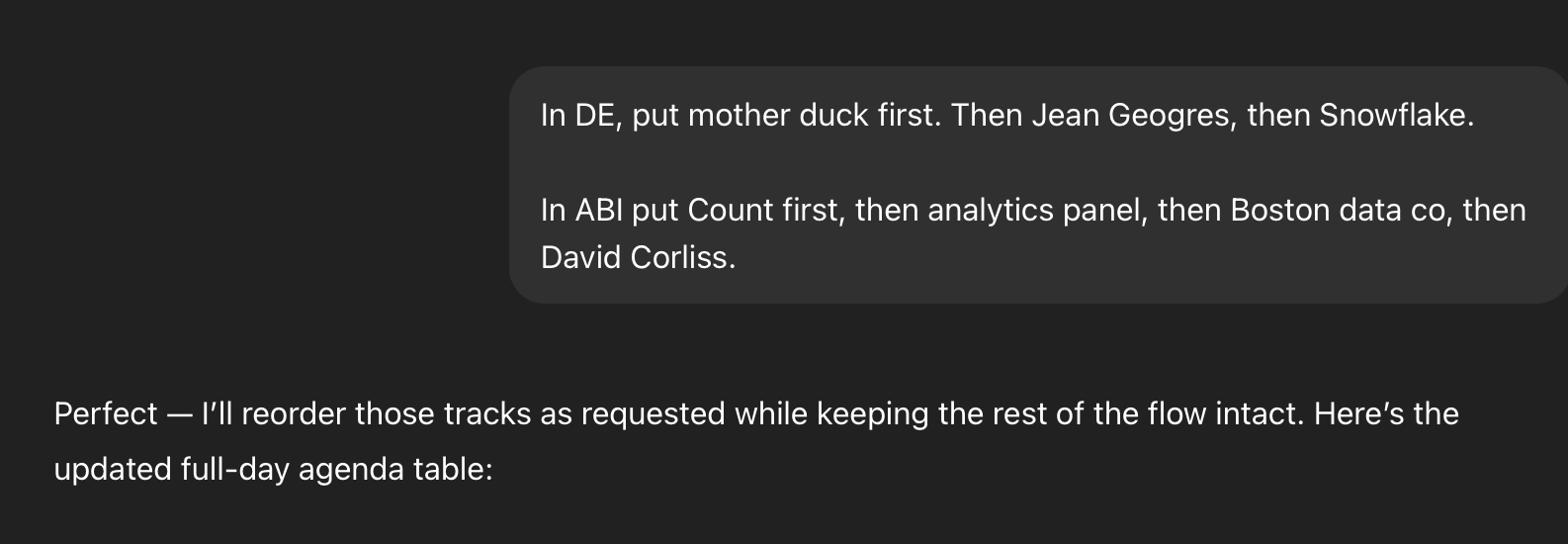
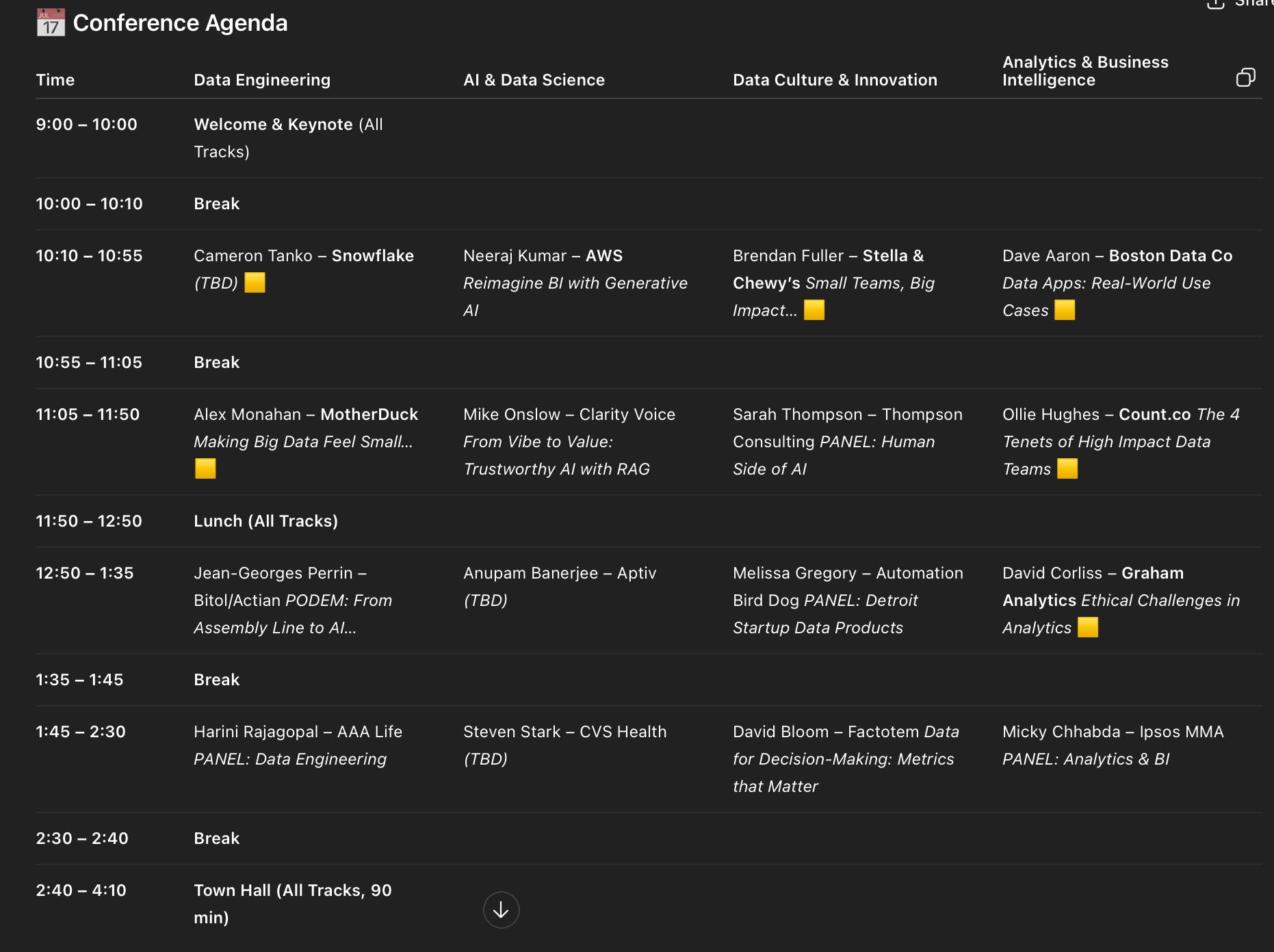
And that was that. The Data in the D Conference agenda was complete in 7 minutes.
Three rules for AI prompting
This wasn’t really about scheduling, it was about how fast teams can co-create with AI. The days of tasking an intern or spending hours in spreadsheets are over. You just need one good prompt and a team that’s not afraid to try.
We followed three simple rules to get this result in minutes, not hours:
Start simple. A “Goldilocks” prompt beats an over-engineered one.
Iterate fast. Every tweak teaches you something.
Show, don’t tell. Screenshots explain more than paragraphs ever could.
Our real win was treating AI like another team member. By keeping prompts simple, moving quickly, and using screenshots instead of long explanations, we saved days of debate and made it out in time to enjoy the last nice Michigan Friday of the year.
Join us at Data in the D!
Data in the D is an annual conference celebrating Detroit’s rich history of innovation in technology. We are bringing the best national speakers and ideas to the Motor City while elevating local voices.
The one day event on Saturday, November 8th includes a ton of amazing talks, a keynote by Joe Reis, an open mic town hall, and a sponsored night out.
Come join us to experience cutting edge data in America’s Comeback City.
Zhamak Dehghani joins us on Super Data Brothers
Zhamak Dehghani, creator of data mesh and founder of Nextdata OS, joins Eric and I on the Super Data Brothers show this week at 12PM Eastern. While we normally do our interview live, Zhamak is busy running one of the world’s most innovative data companies so the interview will be pre-recorded.

I am recording the interview with her today. If you want me to ask Zhamak your question, DM it to me on Substack!
Catch it the show live at 12:00 PM Eastern and on demand here: https://youtube.com/live/CBrCuJ_6-Us
Until next time,
Ryan
 | A guest post by
|
What's the most surprising problem you solved with AI?
This really resonates, I'm always trying to apply AI to planning my dev sprints, such an insightful way to aproach this.